git笔记
What
Git是一个开源的分布式版本控制系统
why
因为大家都在用
好吧,git还是能干点事的
可以回退代码到之前的任意版本。毕竟程序员是一个相当玄学的工作,没准今天随便改两行,代码就跑不起来了,或者突然不需要某个功能了,这时候就可以回退版本便于多人协作。打个比方,两个人分别写一个项目的两个页面,如果没有好用的版本工具,最后上线时就要手动把代码复制粘贴到一起。过于机械化
所以,拯救CV战士,从Git开始
Need to Know
Git文件的四种状态
在学习具体的命令前,还是要先康康文件的状态
.webp)
Untracked: 未跟踪, 此文件在文件夹中, 但并没有加入到git库, 不参与版本控制. 通过git add状态变为Staged.Unmodify: 文件已经入库, 未修改, 即版本库中的文件快照内容与文件夹中完全一致. 这种类型的文件有两种去处, 如果它被修改, 而变为Modified. 如果使用git rm移出版本库, 则成为Untracked文件Modified: 文件已修改, 仅仅是修改, 并没有进行其他的操作. 这个文件需要重新通过git add命令进入staged状态Staged: 暂存状态. 执行git commit则将修改同步到库中, 这时库中的文件和本地文件又变为一致, 文件为Unmodified状态.
Git的几个分区
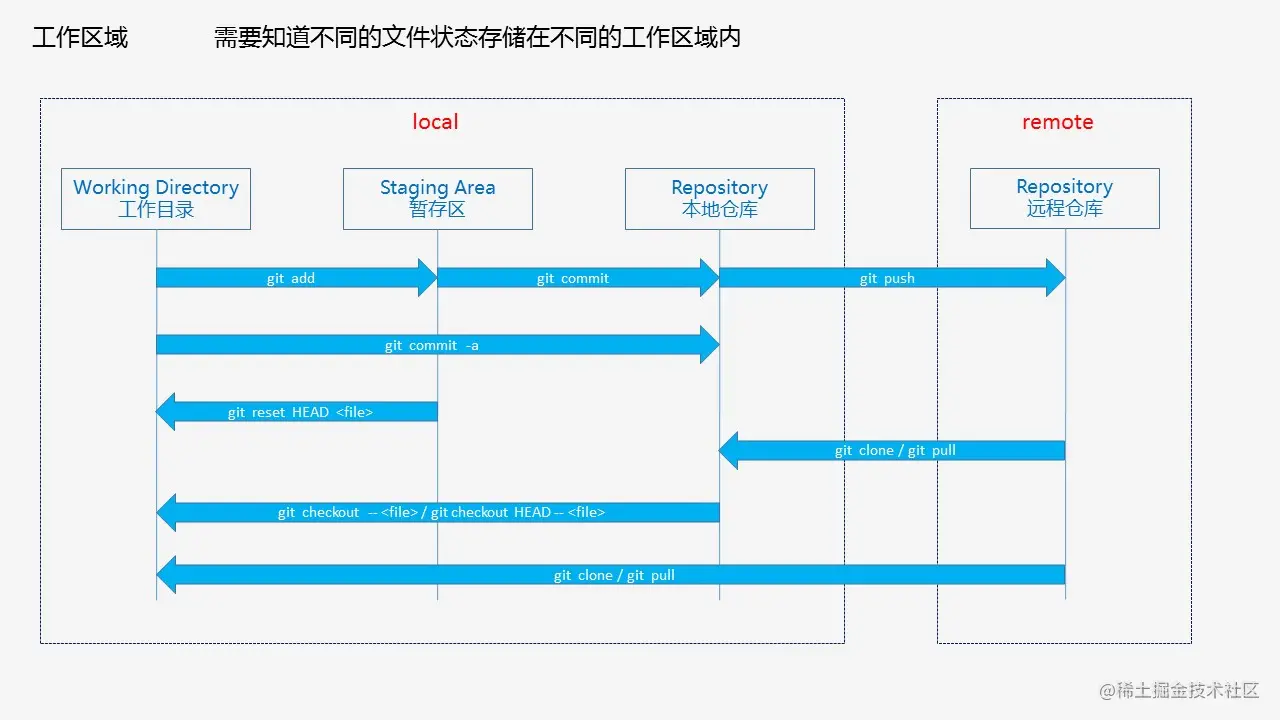
- Workspace:工作区
- Index / Stage:暂存区
- Repository:仓库区(或本地仓库)
- Remote:远程仓库
How
安装git
去官网下载:https://git-scm.com/downloads (opens new window),下载完成后,一路next安装即可
安装完成后,在开始菜单里找到 Git -> Git Bash,蹦出一个类似命令行窗口的东西,就说明Git安装成功! 还需要最后一步设置,在命令行输入:
1 | git config --global user.name "Your Name" |
因为Git是分布式版本控制系统,所以,每个机器都必须自报家门,也需要告诉别人这个commit是谁提交的
你可以使用下面的命令,查看你的配置
1 | git config --global --list |
创建版本库
也不一定必须在空目录下创建Git仓库,选择一个已经有东西的目录直接
git init也是可以的。
1 | 创建仓库 |
1 | 在当前目录新建一个Git代码库(截图用的是这个命令) |
查看信息
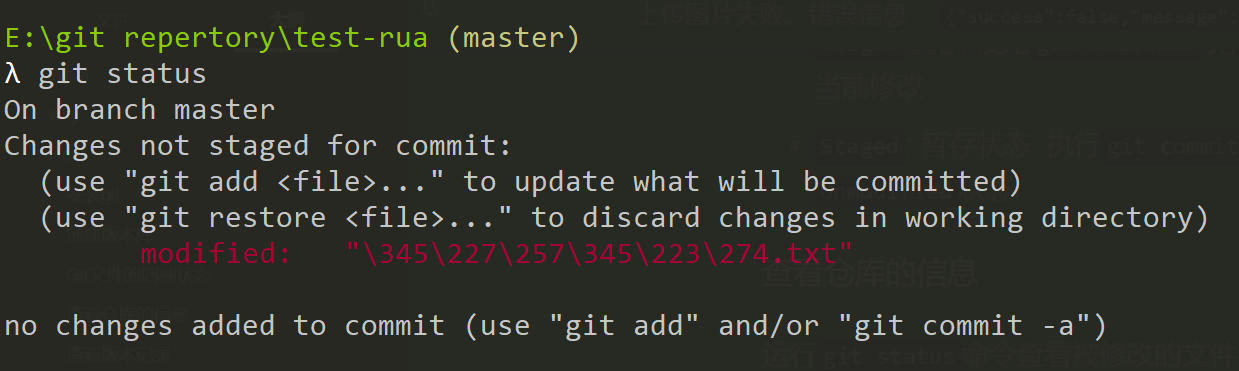
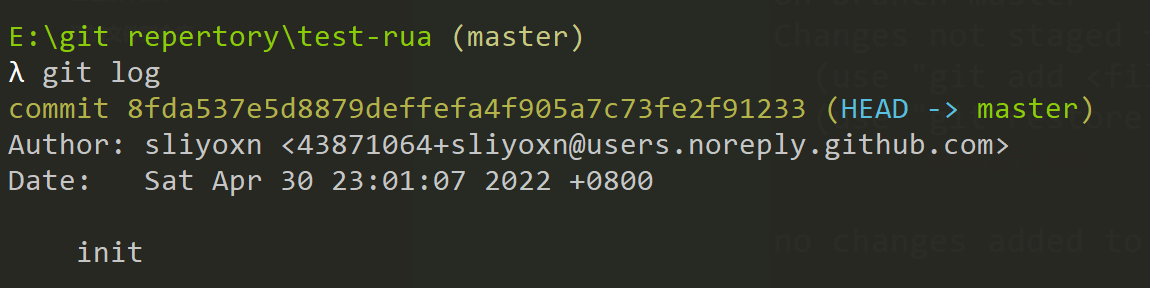
在学习具体的命令前,还是需要知道怎么查看仓库的状态的
1 | # 显示有变更的文件 |
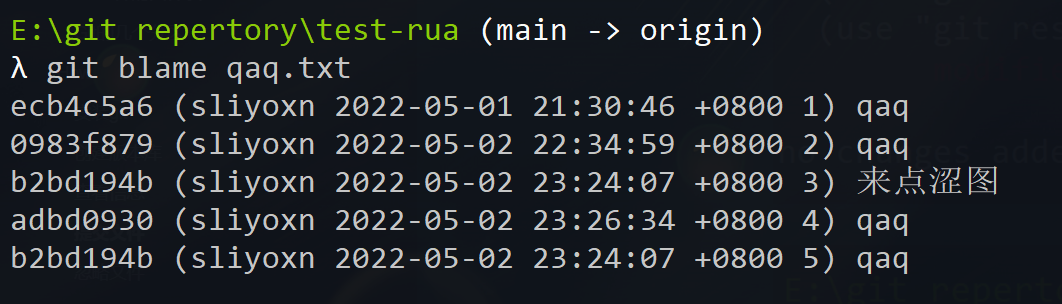
提交文件
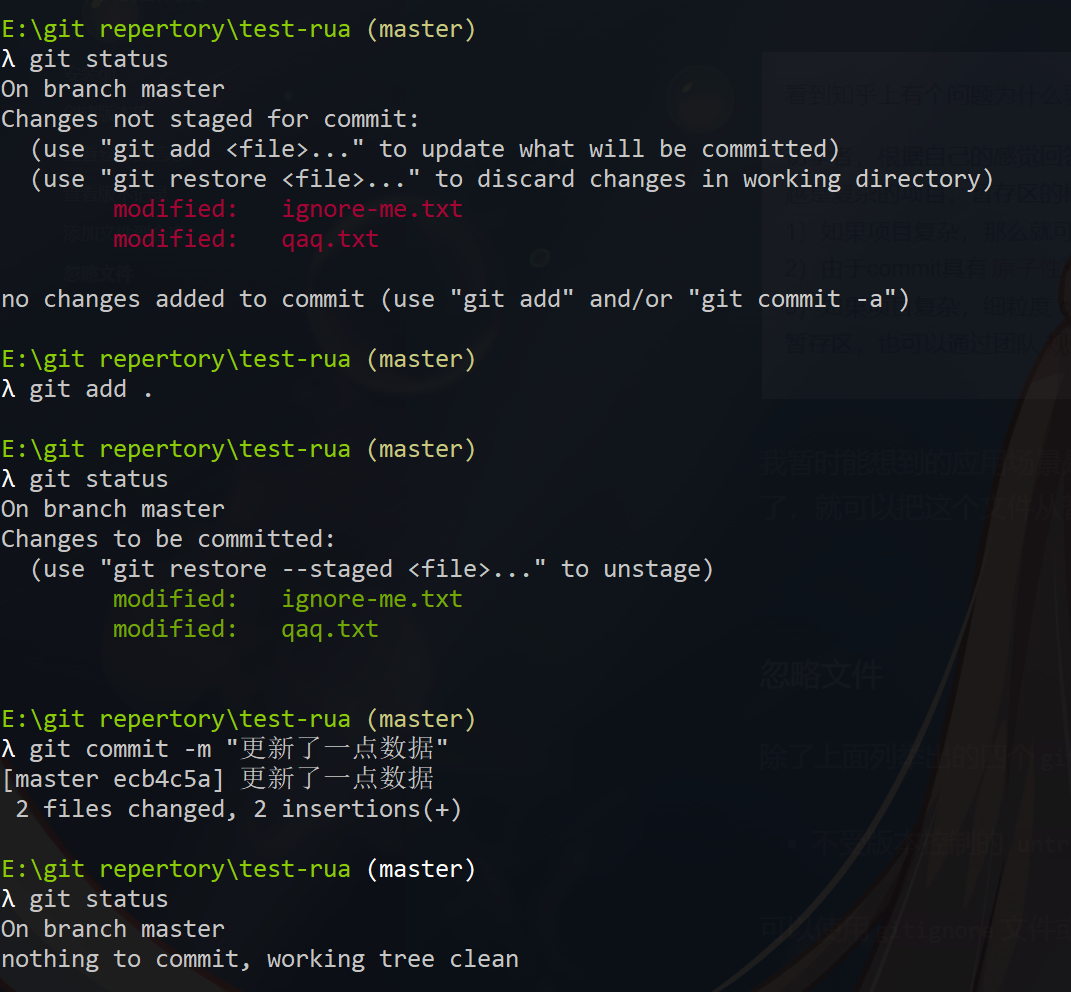
在仓库目录下放入文件,如新建一个test.txt文件,然后使用git add test.txt命令告诉Git,把文件添加到缓存区,然后使用git commit -m "提交描述"告诉Git,把文件提交到仓库。
1 | 缓存区也叫暂存区 |
为什么需要add和commit,我觉得这个解释还是很合理的
我暂时能想到的应用场景是:因为git commit只会提交处于暂存区的文件,如果某次提交时突然不想提交某个文件了,就可以把这个文件从暂存区中移除,这样本次提交就可以不提交某个文件了
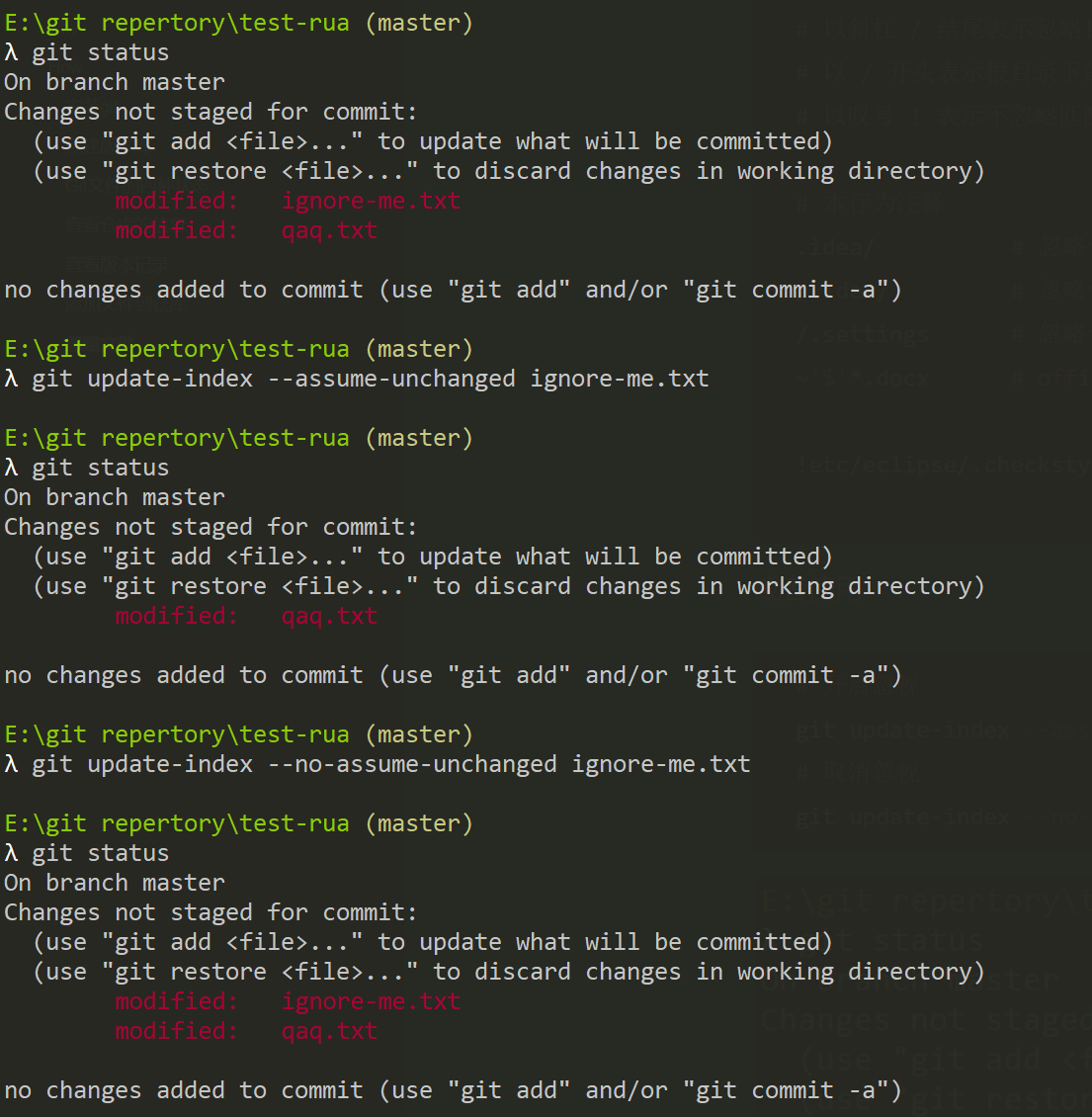
忽略文件
除了上面列举出的四个git文件状态,git文件其实还有一种状态
- 不受版本控制的
untracked状态
可以使用gitignore文件或者git update-index --assume-unchanged <files>命令让某个文件被忽视
1 | 配置.gitignore文件 |
或者使用
1 | 开启忽视 |
效果如下:
撤销修改
方法很多,随便选,反正到时用了GUI也用不上这么多花里胡哨的了
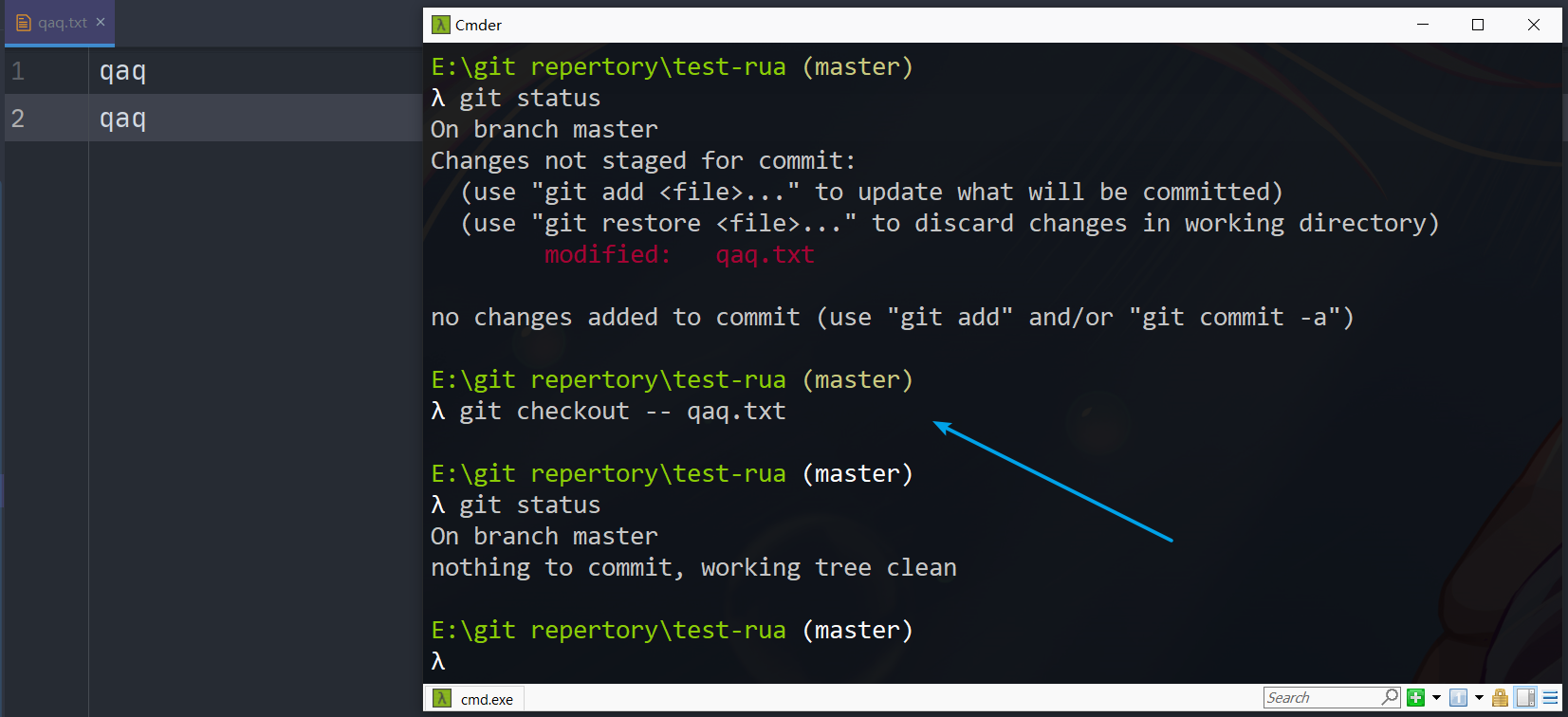
可以使用checkout
1 | 丢弃工作区的修改,并用最近一次的commit内容还原到当前工作区(对文件中内容的操作,无法对添加文件、删除文件起作用) |
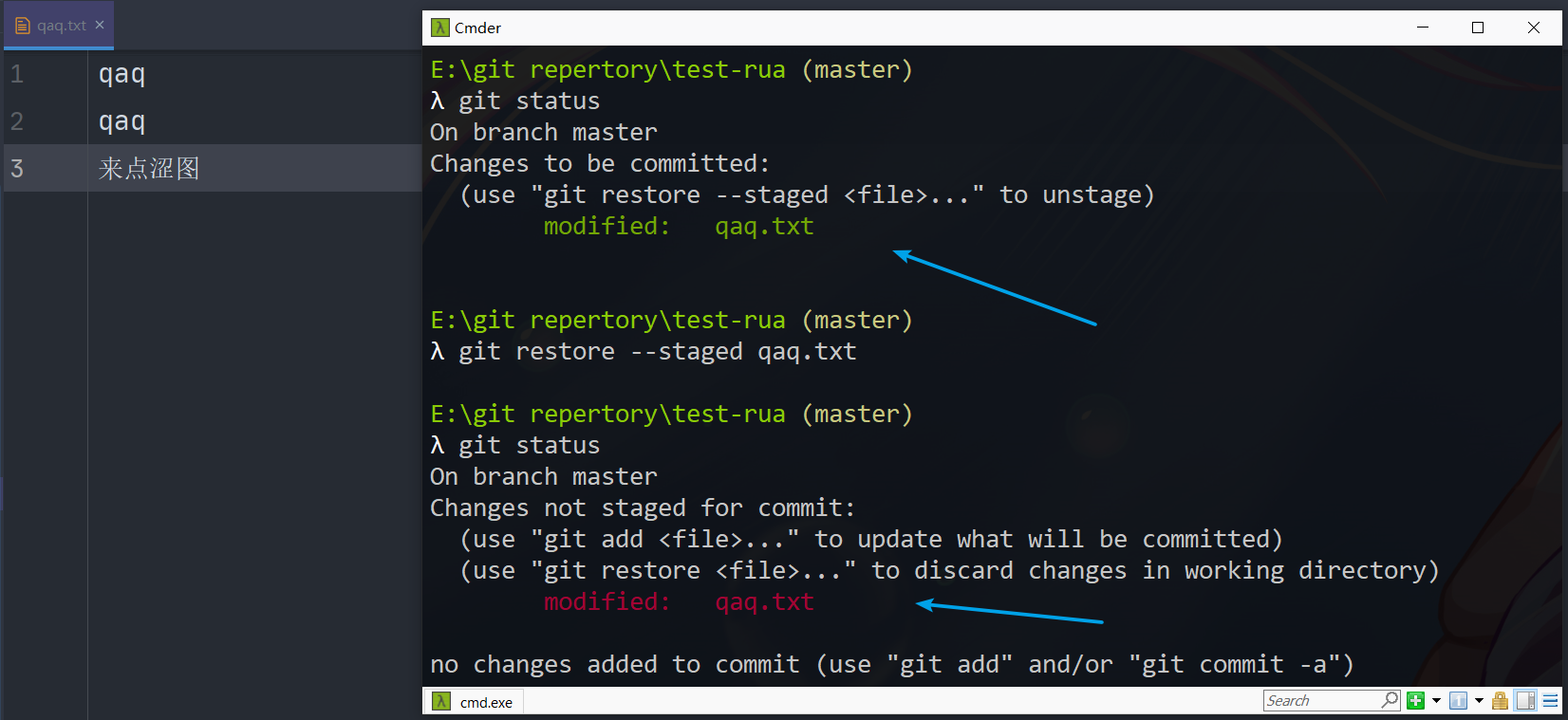
或者restore
1 | 将暂存区的修改重新放回工作区(包括对文件自身的操作,如添加文件、删除文件) |
或者reset
1 | 丢弃暂存区的修改,重新放回工作区,会将暂存区的内容和本地已提交的内容全部恢复到未暂存的状态,不影响原来本地文件(相当于撤销git add 操作,不影响上一次commit后对本地文件的修改) (包括对文件的操作,如添加文件、删除文件) |
看不懂?举几个例子吧
现在的文件和工作区是这样的
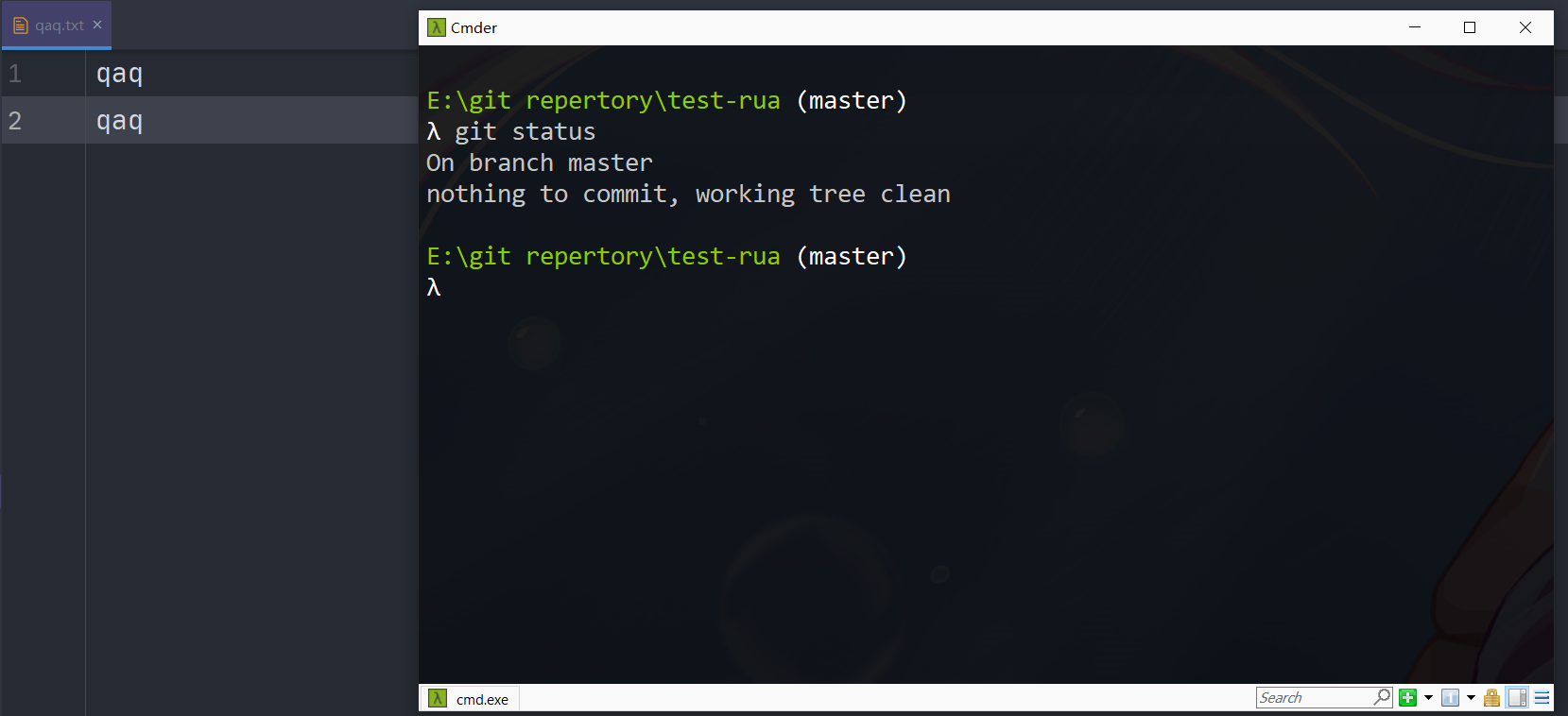
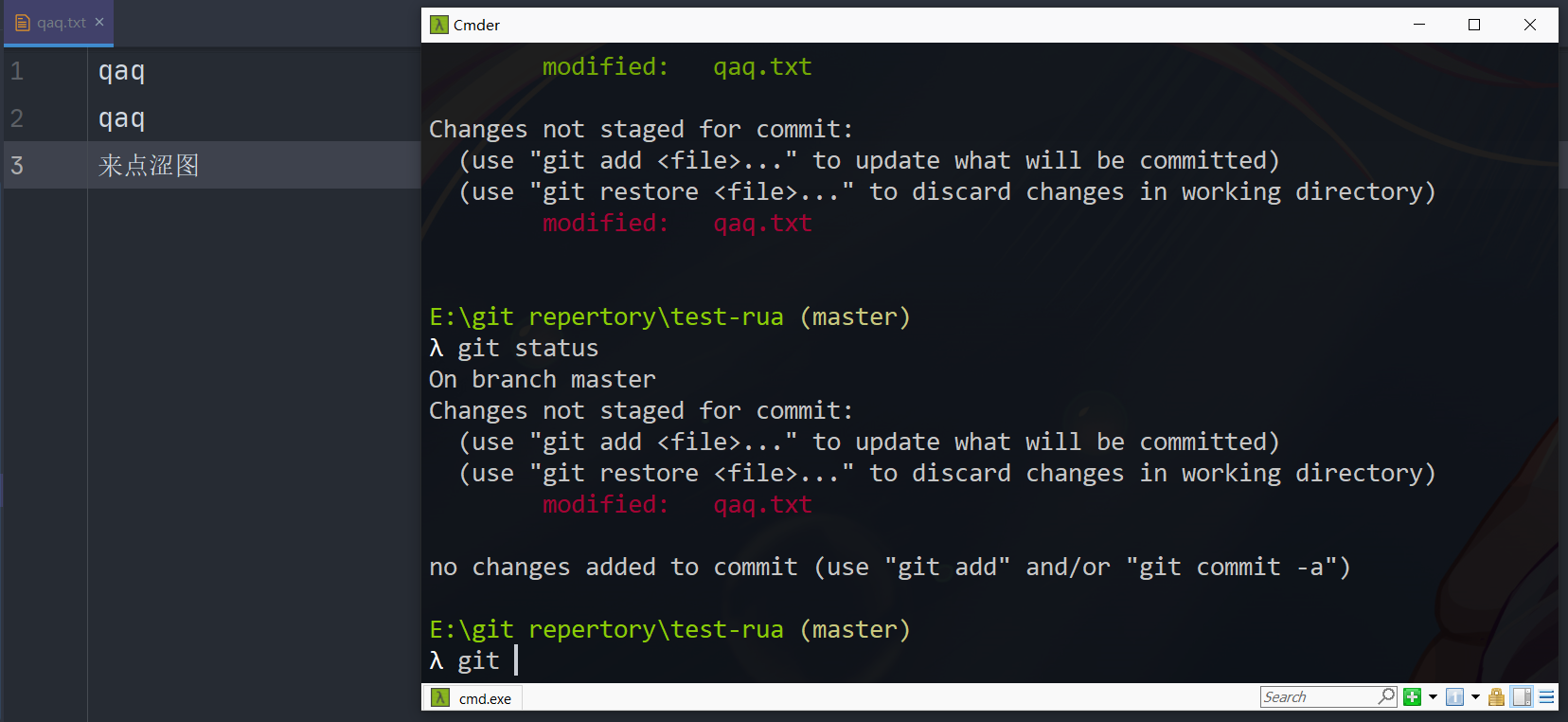
改点内容但是没有add,这时候想要撤销工作区的修改,使用checkout
改了内容并add,想要取消add的状态,使用restore或者reset
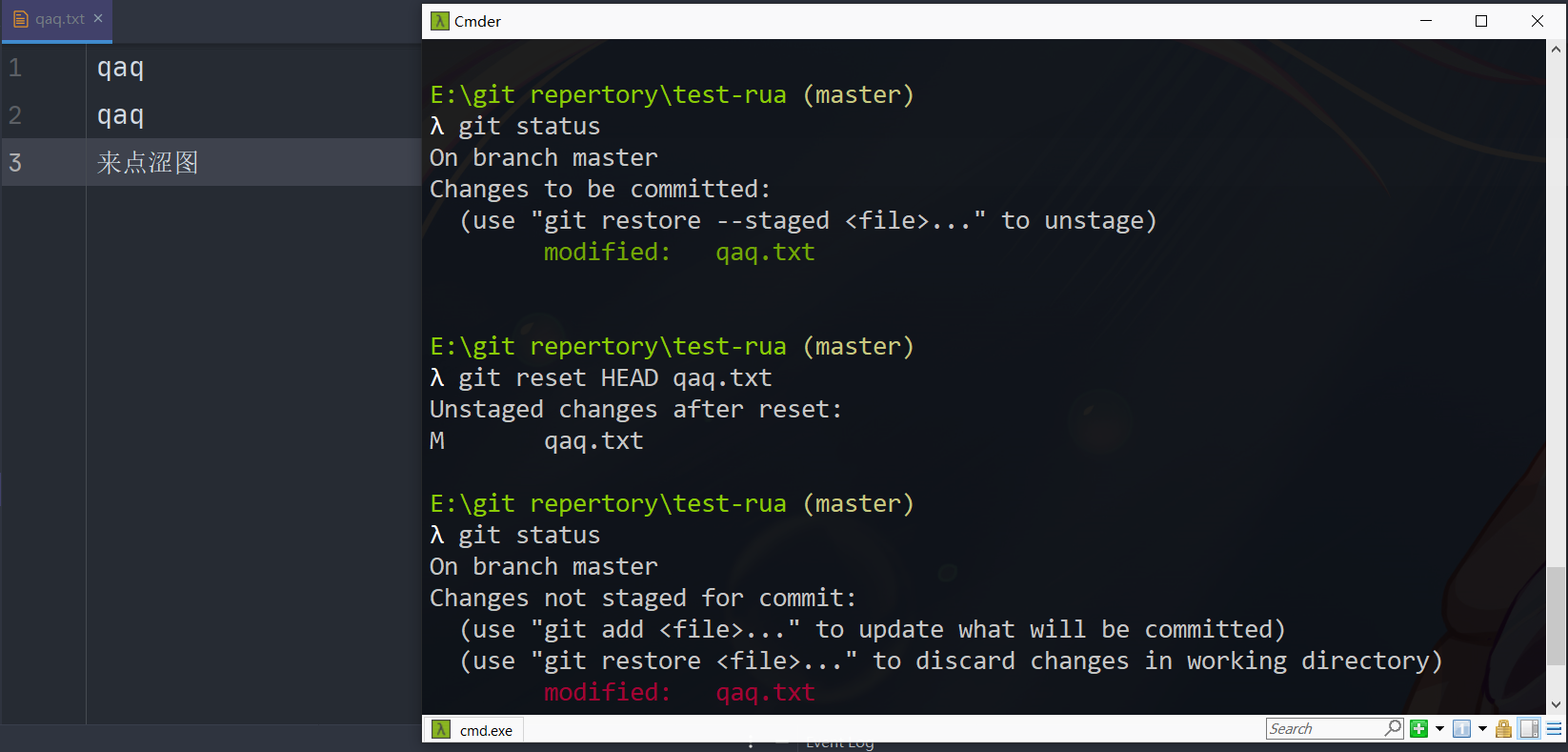
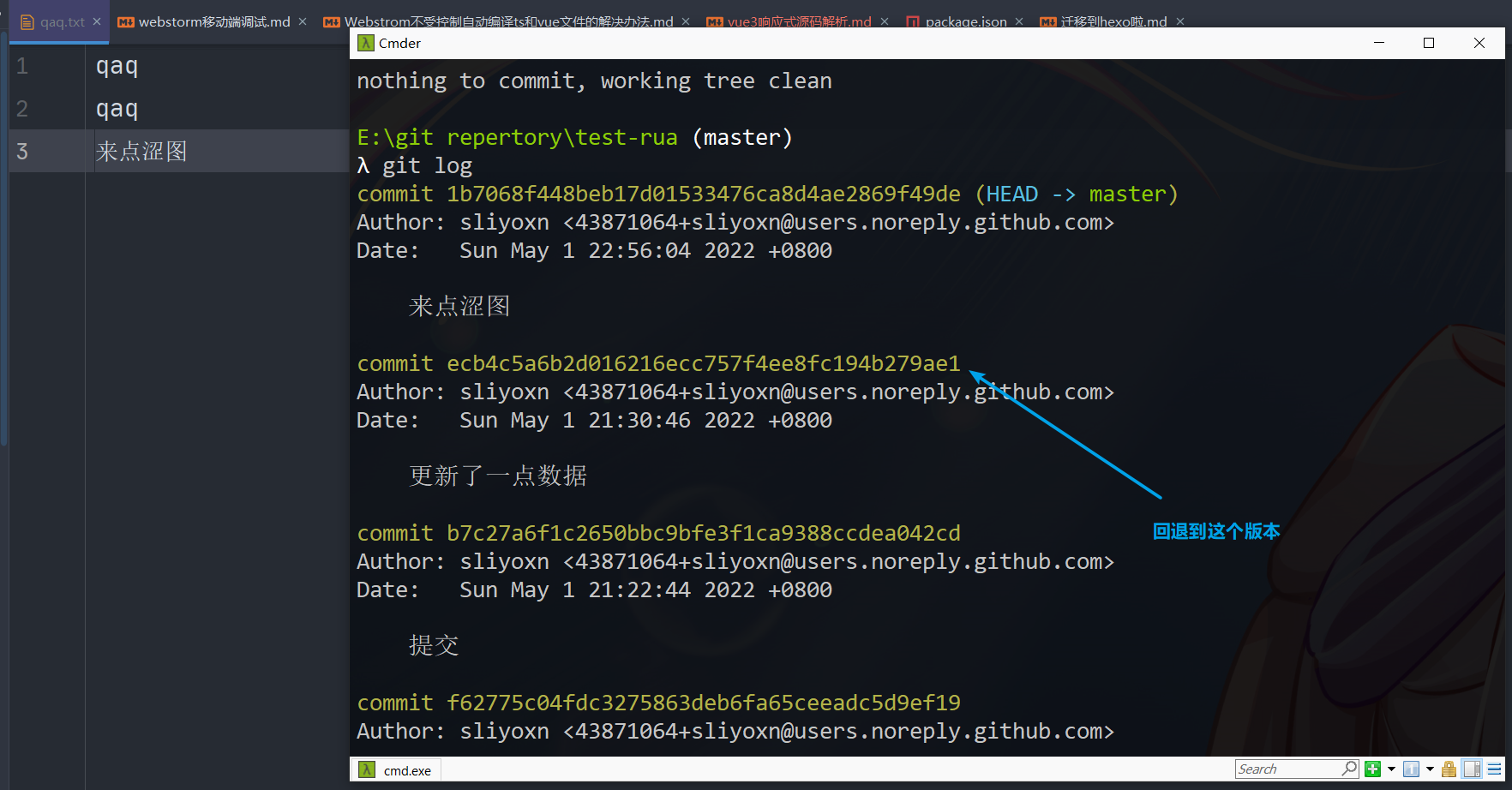
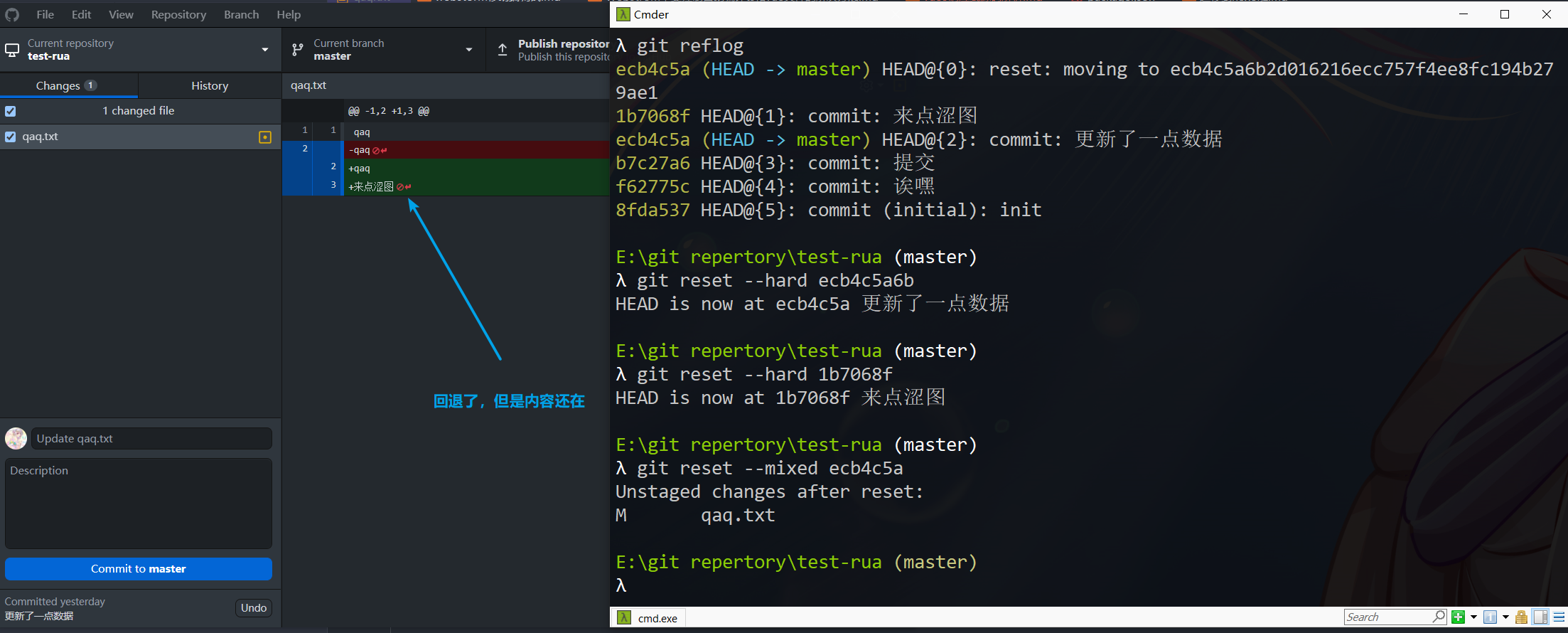
版本回退
首先,Git必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,也就是最新的提交1094adb…(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
一般使用reset回退到之前的版本
1 | 回退到上一个版本 |
执行效果
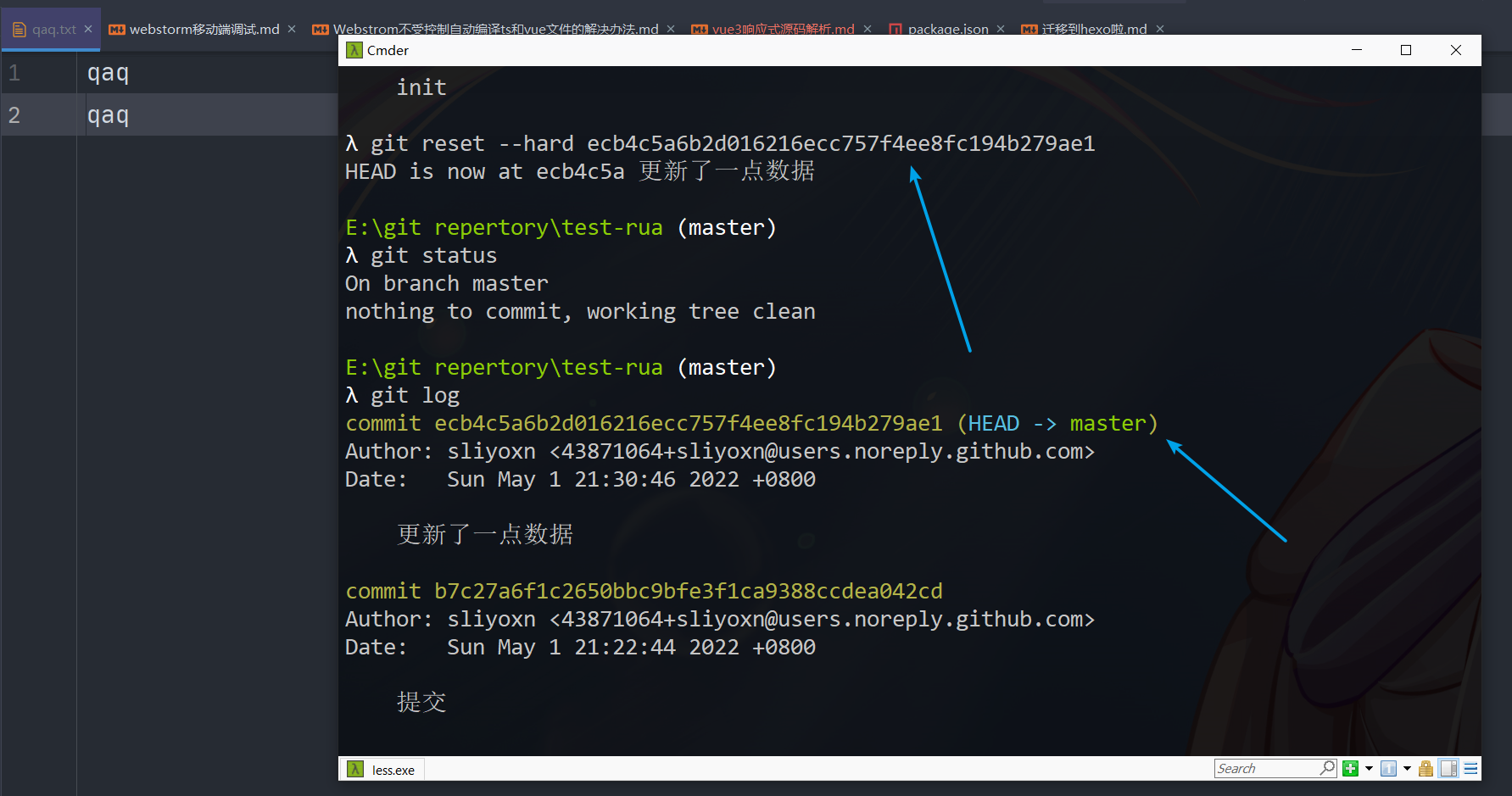
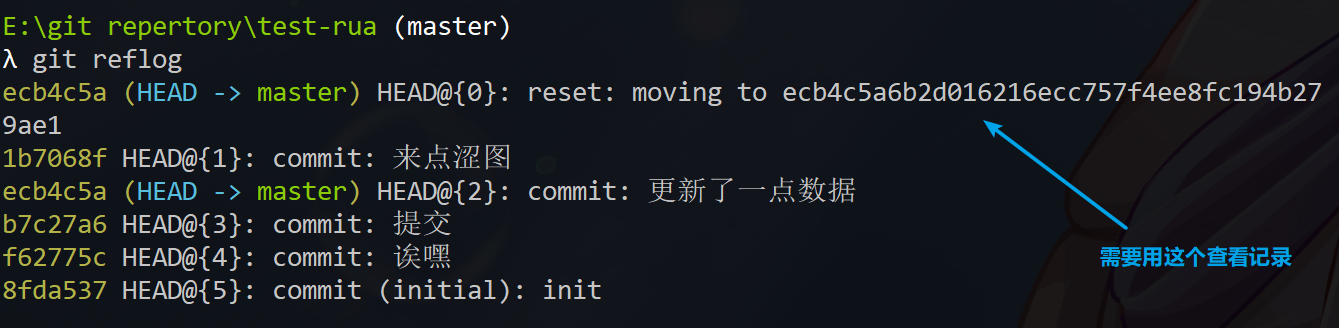
如图,soft和mixed会保留文件内容
分支管理
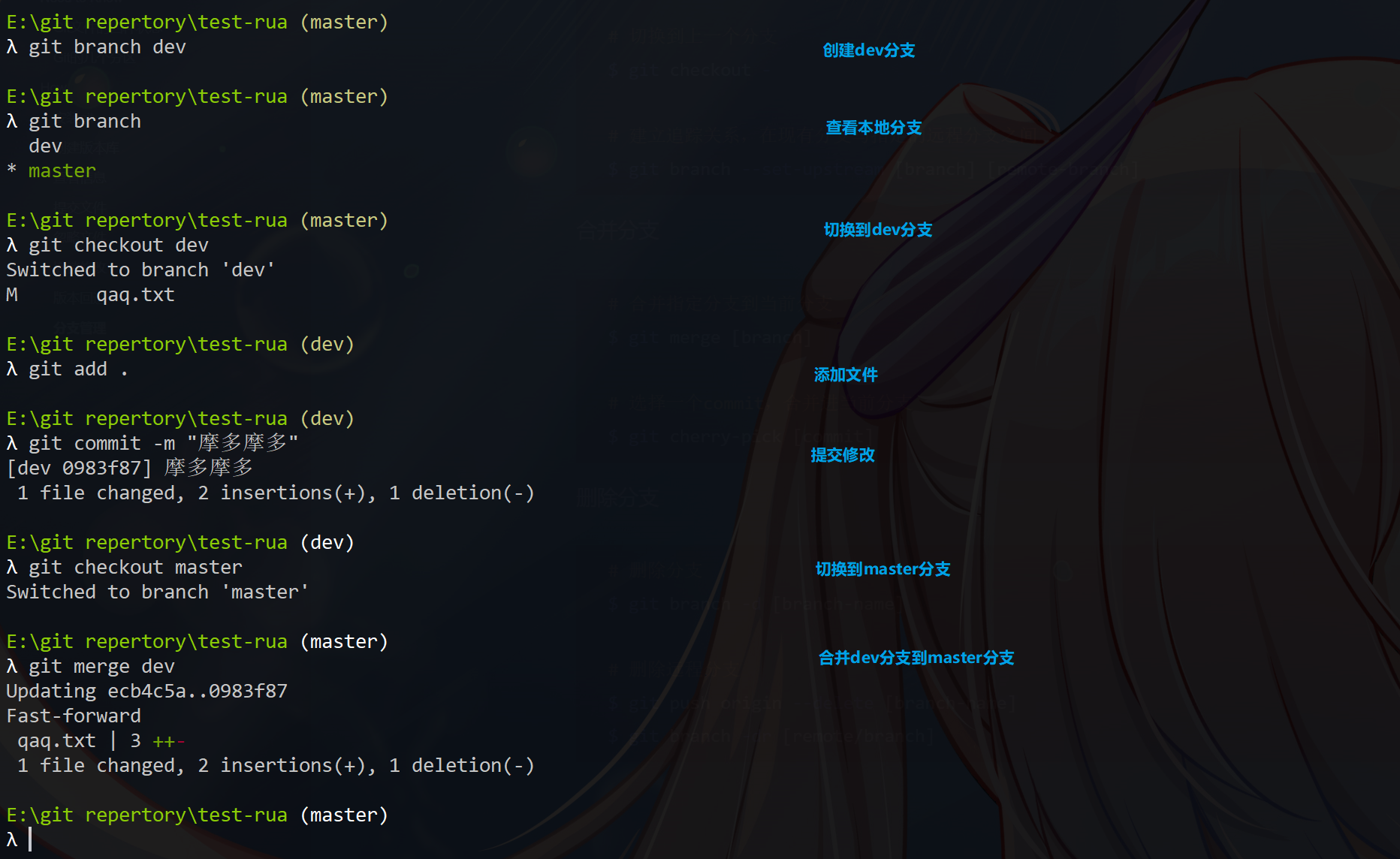
创建分支
1 | 新建一个分支,但依然停留在当前分支 |
查看分支
1 | 列出所有本地分支 |
切换分支
1 | 切换到指定分支,并更新工作区 |
合并分支
1 | 合并指定分支到当前分支 |
删除分支
1 | 删除分支 |
效果如下
单人远程同步
1 | 下载远程仓库的所有变动 |
用的时候,在远端创建git仓库
然后运行下面的命令
1 | create a new repository on the command line |
这里不知道为什么我的浏览器一直没反应…我只能直接用GUI了
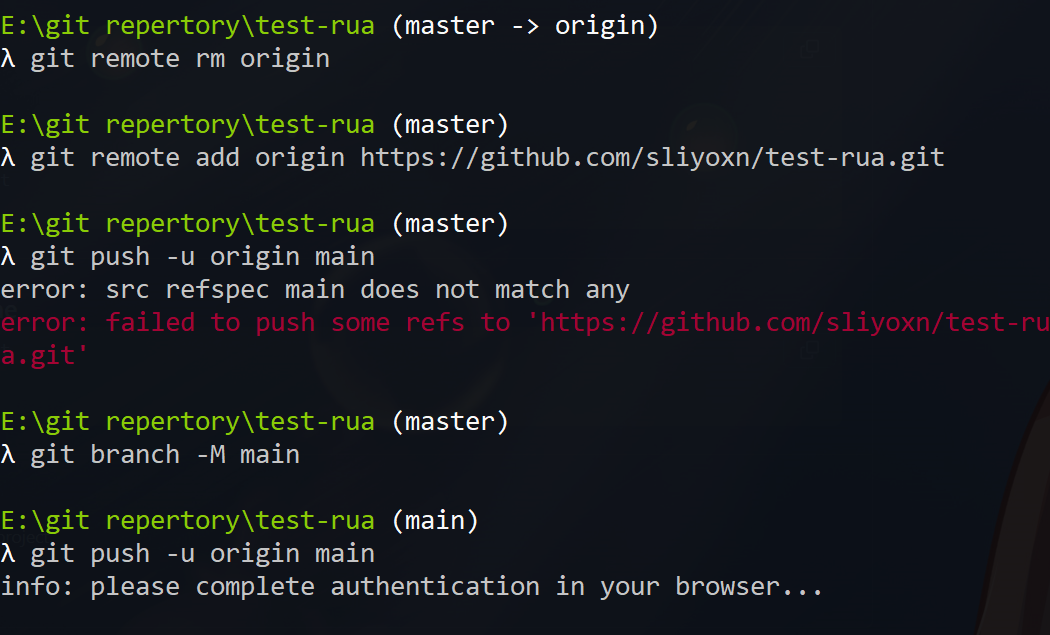
难搞
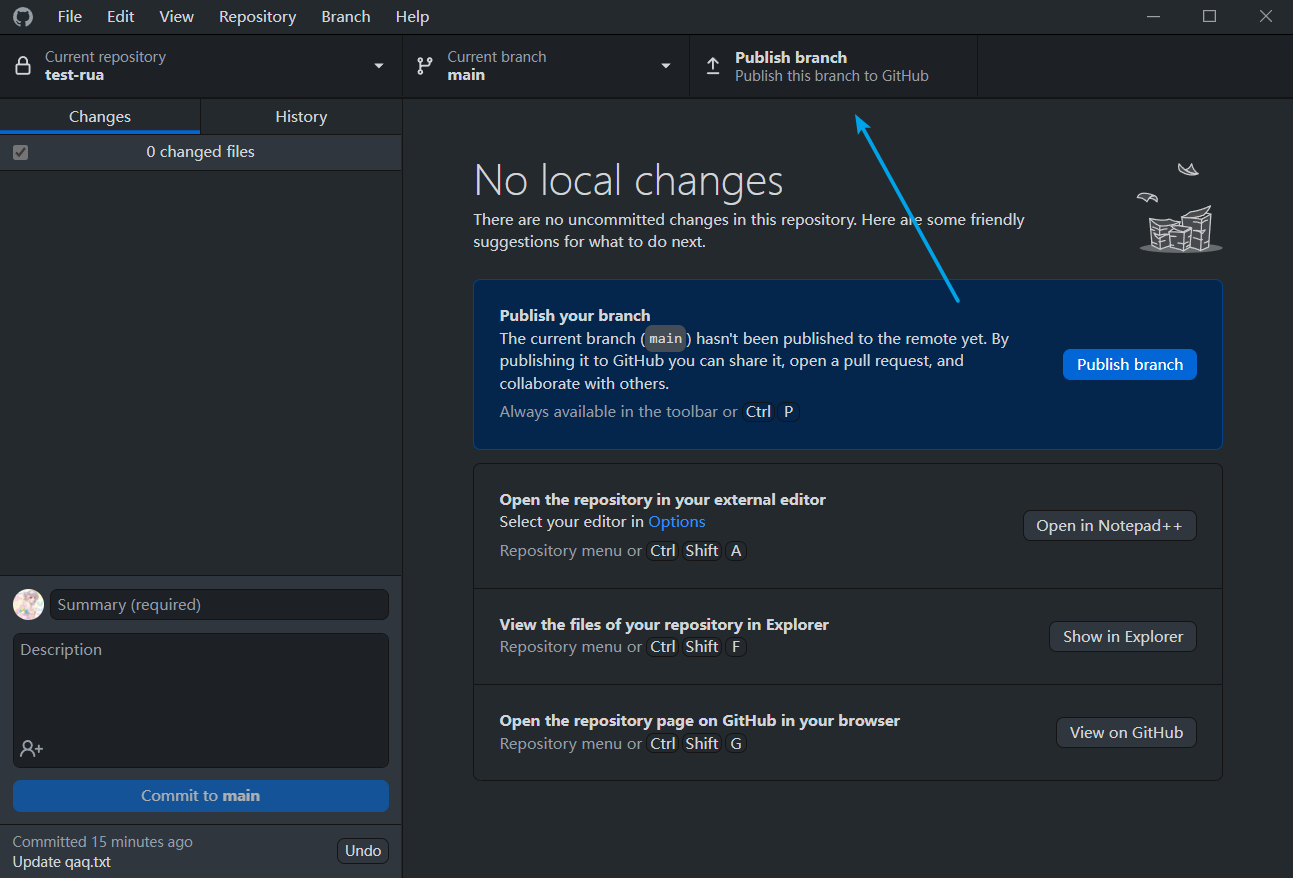
之后,修改并提交即可
多人远程同步
开个小号开个仓库
邀请一下
然后clone
写代码并按之前的操作提交即可
Else
git stash
参考:https://jasonkayzk.github.io/2020/05/03/Git-Stash%E7%94%A8%E6%B3%95%E6%80%BB%E7%BB%93/
git stash命令的作用就是将目前还不想提交的但是已经修改的内容进行保存至堆栈中,后续可以在某个分支上恢复出堆栈中的内容。
使用场景
- 当正在dev分支上开发某个项目,这时项目中出现一个bug,需要紧急修复,但是正在开发的内容只是完成一半,还不想提交,这时可以用git stash命令将修改的内容保存至堆栈区,然后顺利切换到hotfix分支进行bug修复,修复完成后,再次切回到dev分支,从堆栈中恢复刚刚保存的内容。
- 由于疏忽,本应该在dev分支开发的内容,却在master上进行了开发,需要重新切回到dev分支上进行开发,可以用git stash将内容保存至堆栈中,切回到dev分支后,再次恢复内容即可。
当然,热修复时不创建新分支也是理论可行的,虽然修复bug一般是要弄一个
bugfix分支的
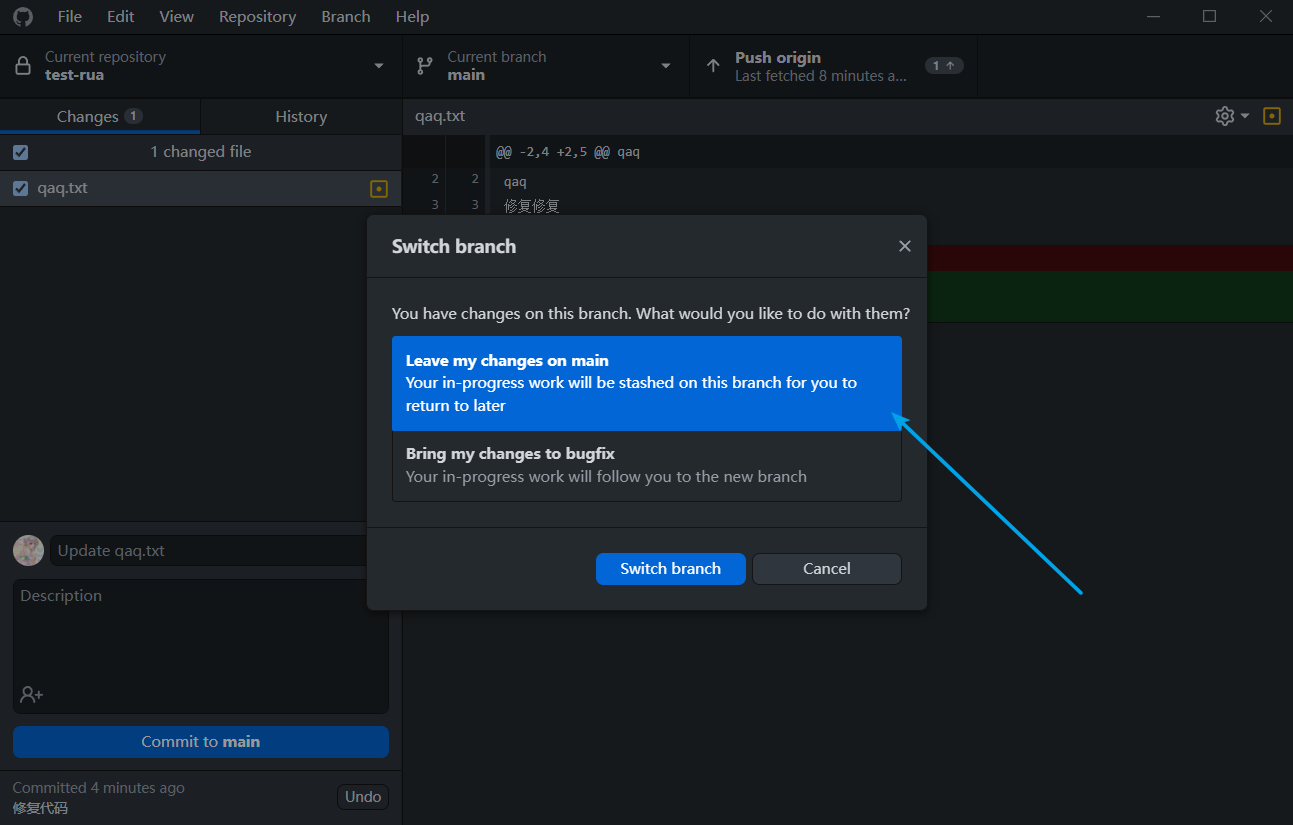
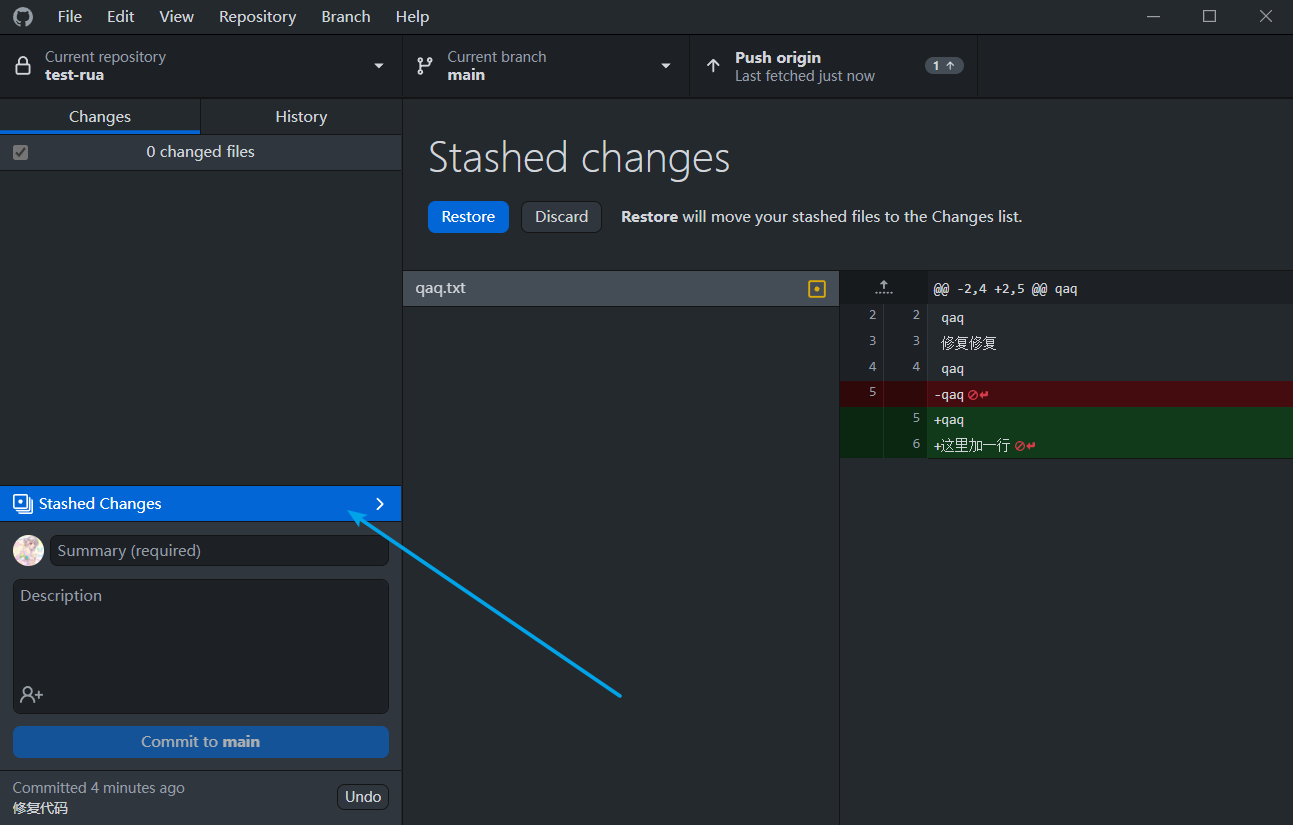
不切换分支时的使用
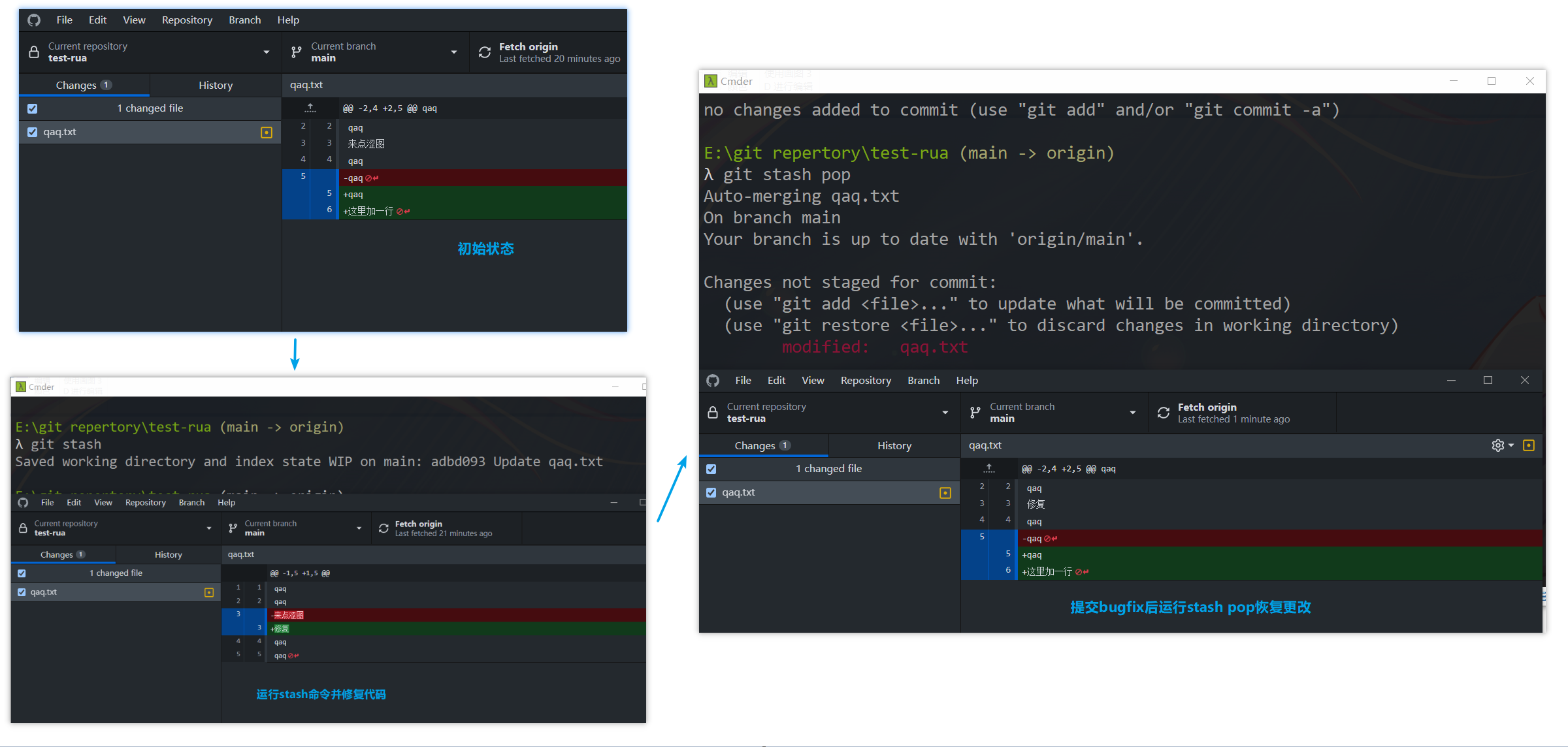
切换分支时的使用
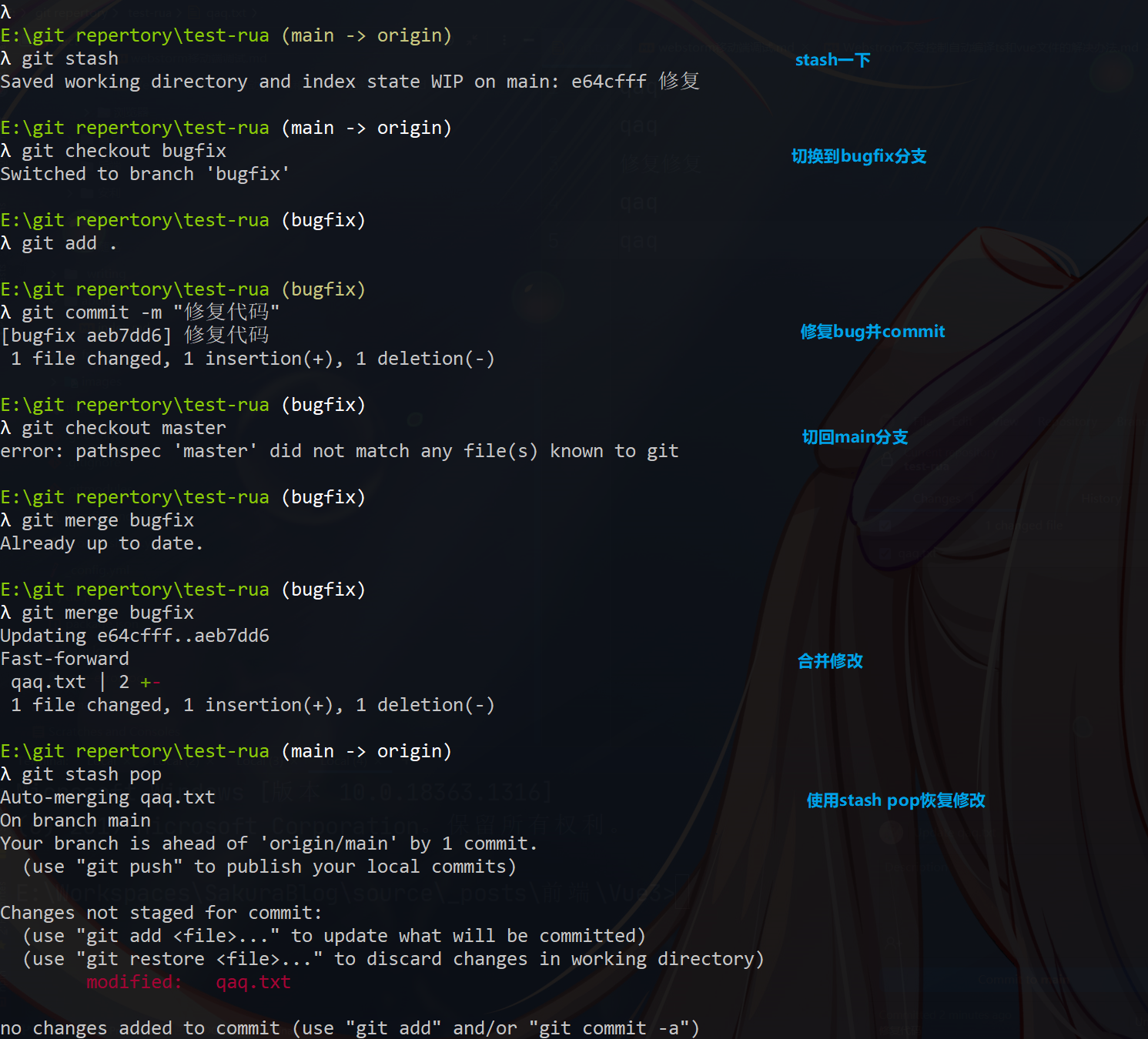
其实就是这个东西
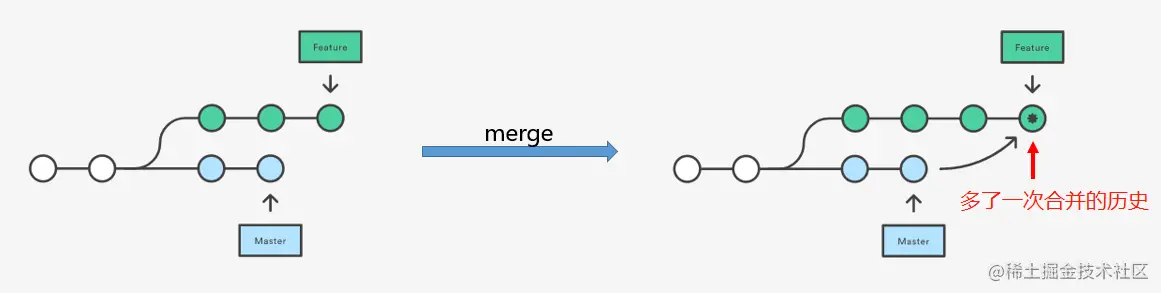
merge和rebase的区别
看图通俗易懂
git merge 有如下特点:
- 只处理一次冲突
- 引入了一次合并的历史记录,合并后的所有
commit会按照提交时间从旧到新排列 - 所有的过程信息更多,可能会提高之后查找问题的难度
git rebase 有如下特点:
- 改变当前分支从
master上拉出分支的位置 - 没有多余的合并历史的记录,且合并后的
commit顺序不一定按照commit的提交时间排列 - 可能会多次解决同一个地方的冲突(有
squash来解决) - 更清爽一些,
master分支上每个commit点都是相对独立完整的功能单元
.webp)
git工作流
根据 Git Flow 的建议,主要的分支有master、develop、hotfix、release 以及 feature 这五种分支,各种分支负责不同的功能。其中 Master 以及 Develop 这两个分支又被称做长期分支,因为他们会一直存活在整个Git Flow 里,而其它的分支大多会因任务结束而被删除。
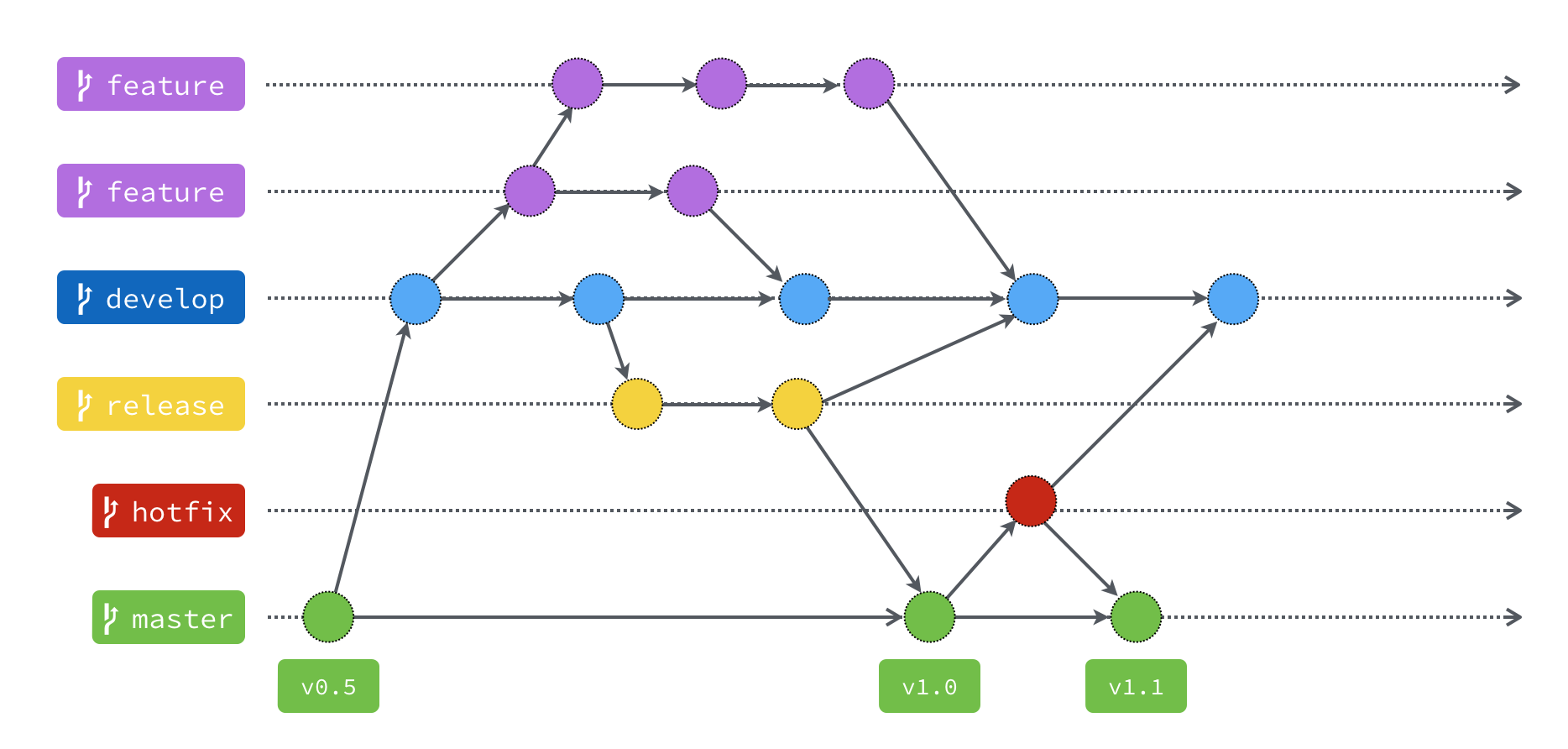
Master 分支
主要是用来放稳定、随时可上线的版本。这个分支的来源只能从别的分支合并过来,开发者不会直接 Commit 到这个分支。
Develop 分支
这个分支主要是所有开发的基础分支,当要新增功能的时候,所有的 Feature 分支都是从这个分支切出去的。而 Feature 分支的功能完成后,也都会合并回来这个分支。
Hotfix 分支
当线上产品发生紧急问题的时候,会从 Master 分支开一个 Hotfix 分支出来进行修复,Hotfix 分支修复完成之后,会合并回 Master 分支,也同时会合并一份到 Develop 分支。
1 | 为什么要合并回 Develop 分支 |
Release 分支
当认为 Develop 分支够成熟了,就可以把 Develop 分支合并到 Release 分支,在这边进行算是上线前的最后测试。测试完成后,Release 分支将会同时合并到 Master 以及 Develop 这两个分支上。 Master 分支是上线版本,而合并回 Develop 分支的目的,是因为可能在 Release 分支上还会测到并修正一些问题,所以需要跟 Develop 分支同步,免得之后的版本又再度出现同样的问题。
Feature 分支
当要开始新增功能的时候,就是使用 Feature 分支的时候了。 Feature 分支都是从 Develop 分支来的,完成之后会再并回 Develop 分支。
